
Jitsi Videobridge Autoscaling with AWS
Jitsi Videobridge acts as the media server hence is the component that consumes the most resources. Scaling becomes a necessity when the traffic starts to increase in your system. The jitsi performance test
shows that a single videobridge can handle 1000 streams on a c5.xlarge server at 550Mbps bitrate. This blog describes how to autoscale jitsi videobridge and please note scaling the whole platform is different
which requires to have multiple shards, load balancing, geo cascading, etc. which will be discussed in a future post.
Why jitsi autoscaling is necessary?
Jitsi videobridge is the component that handles media in jitsi hence is the main server that consumes the most resources.
When the traffic in the server increases (i.e. number of video/audio streams through videobridge) the server resources max out.
(i.e. CPU Usage, Bandwidth). On most servers, it would be the bandwidth that would reach the maximum first.
Also, note that the number of video streams or audio streams is not the number of participants but the number of streams that going across the server.
For example in a meeting of 5 people, roughly 20 streams flow across the server assuming everyone has their video on.
When the number of streams increases the bandwidth and CPU usage of the server increases.
The number of streams increases with both the increase of the number of participants and the increase in the number of parallel conferences.
It will reach a point where the server would max out which on most occasions be the bandwidth.
This would mean we would need more servers to handle the load.
If the traffic does not vary we can simply add more servers to meet the traffic.
But in most scenarios, the traffic varies and the solution needs to adjust to the requirements.
This is where a solution like autoscaling is necessary where the servers would spin up or shut down according to the traffic conditions.
There are few platforms or methods to handle auto-scaling.
- Using AWS native services
- Using Azure native services
- Using Google Cloud-native services
- Using cloud provider servers with Kubernetes to manage the clusters
- Using bare-metal servers with Kubernetes to manage the clusters
In this blog, we would be discussing the first method where we would completely rely on AWS services for handling the scaling end to end.
What services from AWS would be used?
Mainly the following services would be used
AWS EC2 - All the servers would be c5.xlarge (i.e. considering both network and bandwidth capabilities) EC2 instances
AWS EC2 Autoscaling groups - These groups are responsible for handling the autoscaling functionality of the servers. We can set scaling up and scaling down policies, create launch configurations, adjust parameters like max, min capacities of the group.
We will explain more in a bit.
AWS SQS - Keeps the details of the performance of the servers as a message queue.
AWS Cloudwatch - Cloudwatch monitor the servers and fires alarms when the defined thresholds are reached.
High-Level Architecture of the system
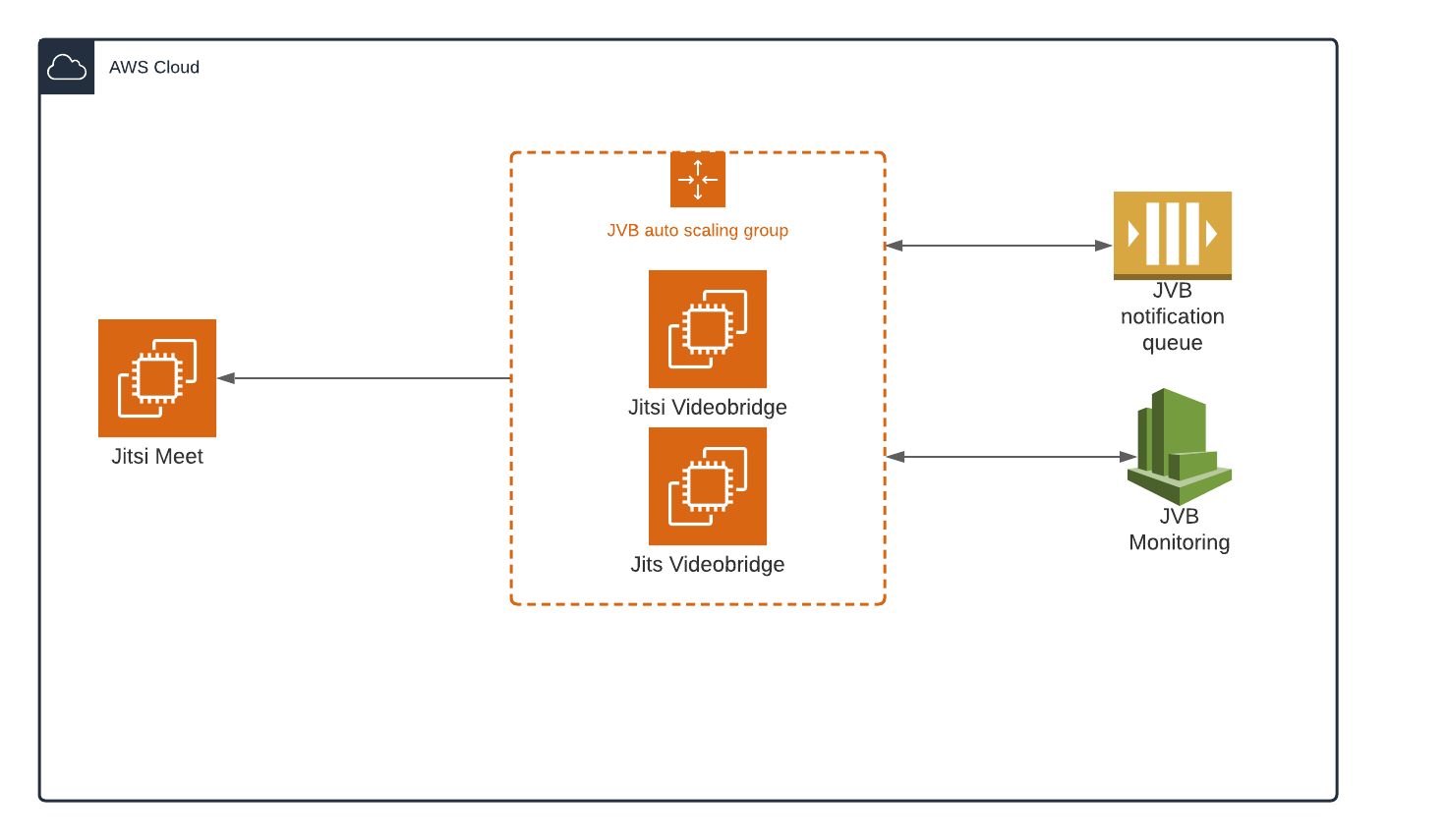

Main components
Jitsi-Meet- Web component of the system and all the videobridges from the group connect to this- Jitsi Videobridge - Media Server of Jitsi which routes all the streams to clients
- Queue - A queue of messages which contain details of servers reaching threshold limits
- JVB monitoring - Monitors all JVB servers and fires an alarm if threshold limit is reached which is then used by the autoscaling group
The Setup
We won't go into details but provide a high-level overview of the steps involved.
Install Jitsi-Meet on an EC2 Server
Install JVB in an EC2 server, create a script in JVB which will check with SQS every minute Finally create an AMI of JVB.
Create a launch configuration in EC2 - This configuration would be used to spin up new servers when scaling up.
For the configuration, use the AMI created in the previous step.
Choose the instance type as per your requirements ( We recommend going for c5.xlarge or above).
Please provide the other information accordingly.
Create an autoscaling group
- Choose the above launch configuration
- Choose the VPC and subnets that you are going to set this up
- Select the group size keeping in mind the traffic conditions. For example, if you do not wish to have more than 10 servers in the group you can set the "Maximum Capacity" to 10.
- Skip the scaling policy for now
- Create a notification for all event types
Go to the created autoscaling group and create a dynamic scaling policy.
Select "Target Tracking scaling" and select Metric type as "Network out".
Give the threshold value considering the network bandwidth capabilities of the server (for example c5.xlarge supports 10Gbps and keeping a safe margin we can choose 70% of this which is 875000000 bytes).
Create another policy with keeping the network out as 375000000 bytes.
Create lifecycle hooks for both instance launch and instance terminate which will be used by the queue to get details about the server.
Create a queue using SQS
- This queue will receive the instance IDs of servers that need to shutdown
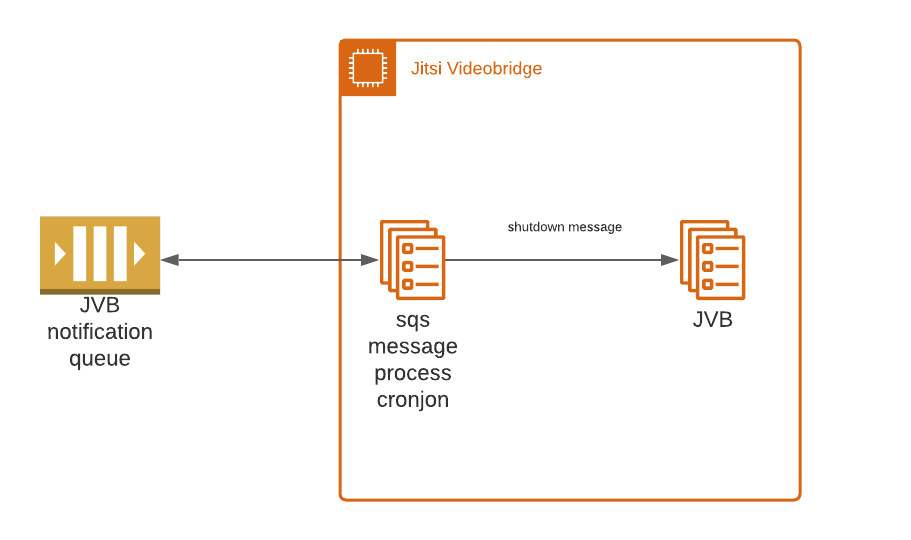

The Process
- When the threshold limits defined in the scaling policy is reached it will either try to spin up or shut down servers.
- If it decides to shut down a server,
- It chooses a server randomly and tries to shut down it. But since we have set up a lifecycle hook it breaks this and puts the instance ID in the queue.
- Each server will check every minute with the SQS whether it needs to shut down by cross-checking the instance IDs of the queue.
- If the server's instance ID matches with the instance ID on the queue it will execute a script to gracefully shut down. This will ensure that the instance will only shut down when the conferences are over.
- If it decides to spin up a new server/s,
- A new server/s will spin up based on the launch configuration.
Conclusion
This blog only explains on a high level how autoscaling is handled in aws.
The setup is complex to be explained in a single blog. We will discuss other methods as well in future blog posts.
If you are interested in hiring us to scale your solution please contact us through support@telzee.io and please visit telzee.io for more details.











